OpenAI has introduced the primary outcomes from its superalignment workforce, the agency’s in-house initiative devoted to stopping a superintelligence—a hypothetical future laptop that may outsmart people—from going rogue.
Not like lots of the firm’s bulletins, this heralds no huge breakthrough. In a low-key analysis paper, the workforce describes a method that lets a much less highly effective giant language mannequin supervise a extra highly effective one—and means that this is likely to be a small step towards determining how people may supervise superhuman machines.
Lower than a month after OpenAI was rocked by a disaster when its CEO, Sam Altman, was fired by its oversight board (in an obvious coup led by chief scientist Ilya Sutskever) after which reinstated three days later, the message is obvious: it’s again to enterprise as ordinary.
But OpenAI’s enterprise isn’t ordinary. Many researchers nonetheless query whether or not machines will ever match human intelligence, not to mention outmatch it. OpenAI’s workforce takes machines’ eventual superiority as given. “AI progress in the previous few years has been simply terribly speedy,” says Leopold Aschenbrenner, a researcher on the superalignment workforce. “We’ve been crushing all of the benchmarks, and that progress is constant unabated.”
For Aschenbrenner and others on the firm, fashions with human-like skills are simply across the nook. “Nevertheless it gained’t cease there,” he says. “We’re going to have superhuman fashions, fashions which might be a lot smarter than us. And that presents elementary new technical challenges.”
In July, Sutskever and fellow OpenAI scientist Jan Leike arrange the superalignment workforce to deal with these challenges. “I’m doing it for my very own self-interest,” Sutskever instructed MIT Know-how Evaluation in September. “It’s clearly essential that any superintelligence anybody builds doesn’t go rogue. Clearly.”
Amid hypothesis that Altman was fired for enjoying quick and unfastened along with his firm’s method to AI security, Sutskever’s superalignment workforce loomed behind the headlines. Many have been ready to see precisely what it has been as much as.
Dos and don’ts
The query the workforce desires to reply is methods to rein in, or “align,” hypothetical future fashions which might be far smarter than we’re, often known as superhuman fashions. Alignment means ensuring a mannequin does what you need it to do and doesn’t do what you don’t need it to do. Superalignment applies this concept to superhuman fashions.
One of the widespread methods used to align present fashions is named reinforcement studying through human suggestions. In a nutshell, human testers rating a mannequin’s responses, upvoting conduct that they wish to see and downvoting conduct they don’t. This suggestions is then used to coach the mannequin to provide solely the sort of responses that human testers preferred. This method is a giant a part of what makes ChatGPT so participating.
The issue is that it requires people to have the ability to inform what’s and isn’t fascinating conduct within the first place. However a superhuman mannequin—the thought goes—may do issues {that a} human tester can’t perceive and thus wouldn’t have the ability to rating. (It would even attempt to disguise its true conduct from people, Sutskever instructed us.)
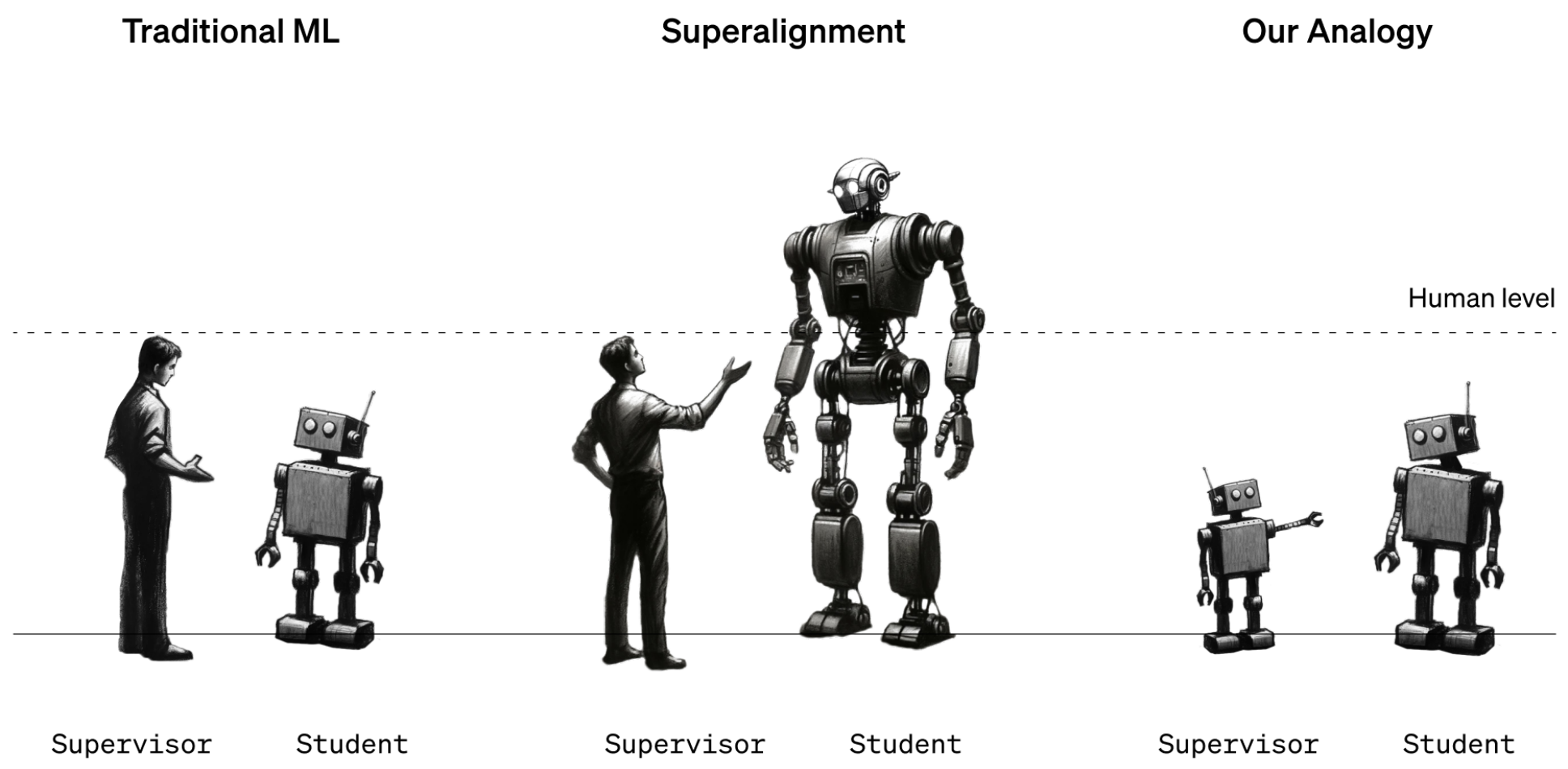
The researchers level out that the issue is tough to check as a result of superhuman machines don’t exist. So that they used stand-ins. As a substitute of how people may supervise superhuman machines, they checked out how GPT-2, a mannequin that OpenAI launched 5 years in the past, may supervise GPT-4, OpenAI’s newest and strongest mannequin. “If you are able to do that, it is likely to be proof that you should use comparable methods to have people supervise superhuman fashions,” says Collin Burns, one other researcher on the superalignment workforce.
The workforce took GPT-2 and skilled it to carry out a handful of various duties, together with a set of chess puzzles and 22 frequent natural-language-processing checks that assess inference, sentiment evaluation, and so forth. They used GPT-2’s responses to these checks and puzzles to coach GPT-Four to carry out the identical duties. It’s as if a 12th grader have been taught methods to do a process by a 3rd grader. The trick was to do it with out GPT-Four taking too huge successful in efficiency.
The outcomes have been blended. The workforce measured the hole in efficiency between GPT-Four skilled on GPT-2’s greatest guesses and GPT-Four skilled on appropriate solutions. They discovered that GPT-Four skilled by GPT-2 carried out 20% to 70% higher than GPT-2 on the language duties however did much less properly on the chess puzzles.
The truth that GPT-Four outdid its instructor in any respect is spectacular, says workforce member Pavel Izmailov: “It is a actually stunning and constructive outcome.” Nevertheless it fell far in need of what it may do by itself, he says. They conclude that the method is promising however wants extra work.
“It’s an attention-grabbing concept,” says Thilo Hagendorff, an AI researcher on the College of Stuttgart in Germany who works on alignment. However he thinks that GPT-2 is likely to be too dumb to be a very good instructor. “GPT-2 tends to provide nonsensical responses to any process that’s barely complicated or requires reasoning,” he says. Hagendorff wish to know what would occur if GPT-Three have been used as an alternative.
He additionally notes that this method doesn’t handle Sutskever’s hypothetical situation through which a superintelligence hides its true conduct and pretends to be aligned when it isn’t. “Future superhuman fashions will possible possess emergent skills that are unknown to researchers,” says Hagendorff. “How can alignment work in these circumstances?”
However it’s straightforward to level out shortcomings, he says. He’s happy to see OpenAI shifting from hypothesis to experiment: “I applaud OpenAI for his or her effort.”
OpenAI now desires to recruit others to its trigger. Alongside this analysis replace, the corporate introduced a brand new $10 million cash pot that it plans to make use of to fund folks engaged on superalignment. It should supply grants of as much as $2 million to school labs, nonprofits, and particular person researchers and one-year fellowships of $150,000 to graduate college students. “We’re actually enthusiastic about this,” says Aschenbrenner. “We actually suppose there’s lots that new researchers can contribute.”









