Enlarge (credit score: CHRISTOPH BURGSTEDT/SCIENCE PHOTO LIBRARY)
The success of ChatGPT and its rivals relies on what’s termed emergent behaviors. These methods, referred to as massive language fashions (LLMs), weren’t educated to output natural-sounding language (or efficient malware); they have been merely tasked with monitoring the statistics of phrase utilization. However, given a big sufficient coaching set of language samples and a sufficiently complicated neural community, their coaching resulted in an inner illustration that “understood” English utilization and a big compendium of details. Their complicated habits emerged from a far easier coaching.
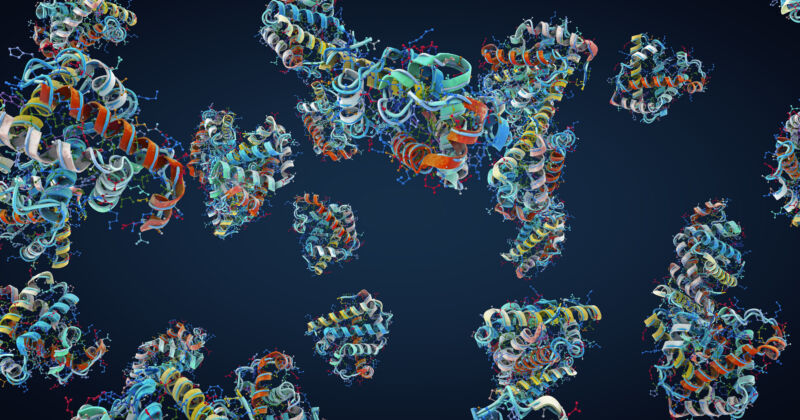
A workforce at Meta has now reasoned that this form of emergent understanding should not be restricted to languages. So it has educated an LLM on the statistics of the looks of amino acids inside proteins and used the system’s inner illustration of what it realized to extract details about the construction of these proteins. The end result is just not fairly pretty much as good as the very best competing AI methods for predicting protein buildings, however it’s significantly quicker and nonetheless getting higher.
LLMs: Not only for language
The very first thing it’s worthwhile to know to grasp this work is that, whereas the time period “language” within the title “LLM” refers to their unique growth for language processing duties, they’ll probably be used for a wide range of functions. So, whereas language processing is a standard use case for LLMs, these fashions produce other capabilities as effectively. In reality, the time period “Massive” is way extra informative, in that every one LLMs have a lot of nodes—the “neurons” in a neural community—and a fair bigger variety of values that describe the weights of the connections amongst these nodes. Whereas they have been first developed to course of language, they’ll probably be used for a wide range of duties.
Learn 17 remaining paragraphs | Feedback









