For a reporter who covers AI, one of many largest tales this 12 months has been the rise of huge language fashions. These are AI fashions that produce textual content a human might need written—typically so convincingly they’ve tricked folks into pondering they’re sentient.
These fashions’ energy comes from troves of publicly accessible human-created textual content that has been hoovered from the web. It acquired me pondering: What knowledge do these fashions have on me? And the way might it’s misused?
It’s not an idle query. I’ve been paranoid about posting something about my private life publicly since a bruising expertise a couple of decade in the past. My photos and private info had been splashed throughout a web based discussion board, then dissected and ridiculed by individuals who didn’t like a column I’d written for a Finnish newspaper.
As much as that time, like many individuals, I’d carelessly littered the web with my knowledge: private weblog posts, embarrassing picture albums from nights out, posts about my location, relationship standing, and political preferences, out within the open for anybody to see. Even now, I’m nonetheless a comparatively public determine, since I’m a journalist with primarily my total skilled portfolio only one on-line search away.
OpenAI has offered restricted entry to its well-known massive language mannequin, GPT-3, and Meta lets folks mess around with its mannequin OPT-175B although a publicly accessible chatbot known as BlenderBot 3.
I made a decision to check out each fashions, beginning by asking GPT-3: Who’s Melissa Heikkilä?

After I learn this, I froze. Heikkilä was the 18th most typical surname in my native Finland in 2022, however I’m one of many solely journalists writing in English with that identify. It shouldn’t shock me that the mannequin related it with journalism. Giant language fashions scrape huge quantities of information from the web, together with information articles and social media posts, and names of journalists and authors seem fairly often.
And but, it was jarring to be confronted with one thing that was really right. What else does it know??
But it surely rapidly turned clear the mannequin doesn’t actually have something on me. It quickly began giving me random textual content it had collected about Finland’s 13,931 different Heikkiläs, or different Finnish issues.

Lol. Thanks, however I believe you imply Lotta Heikkilä, who made it to the pageant’s high 10 however didn’t win.


Seems I’m a no person. And that’s factor on the earth of AI.
Giant language fashions (LLMs), corresponding to OpenAI’s GPT-3, Google’s LaMDA, and Meta’s OPT-175B, are crimson sizzling in AI analysis, and they’re changing into an more and more integral a part of the web’s plumbing. LLMs are getting used to energy chatbots that assist with customer support, to create extra highly effective on-line search, and to assist software program builders write code.
In case you’ve posted something even remotely private in English on the web, chances are high your knowledge could be a part of among the world’s hottest LLMs.
Tech firms corresponding to Google and OpenAI don’t launch details about the information units which have been used to construct their language fashions, however they inevitably embody some delicate private info, corresponding to addresses, cellphone numbers, and e mail addresses.
That poses a “ticking time bomb” for privateness on-line, and opens up a plethora of safety and authorized dangers, warns Florian Tramèr, an affiliate professor of pc science at ETH Zürich who has studied LLMs. In the meantime, efforts to enhance the privateness of machine studying and regulate the expertise are nonetheless of their infancy.
My relative anonymity on-line might be potential because of the truth that I’ve lived my total life in Europe, and the GDPR, the EU’s strict knowledge safety regime, has been in place since 2018.
My boss, MIT Know-how Evaluation editor in chief Mat Honan, nonetheless, is unquestionably a any individual.
Each GPT-Three and BlenderBot “knew” who he was. That is what GPT-Three had on him.
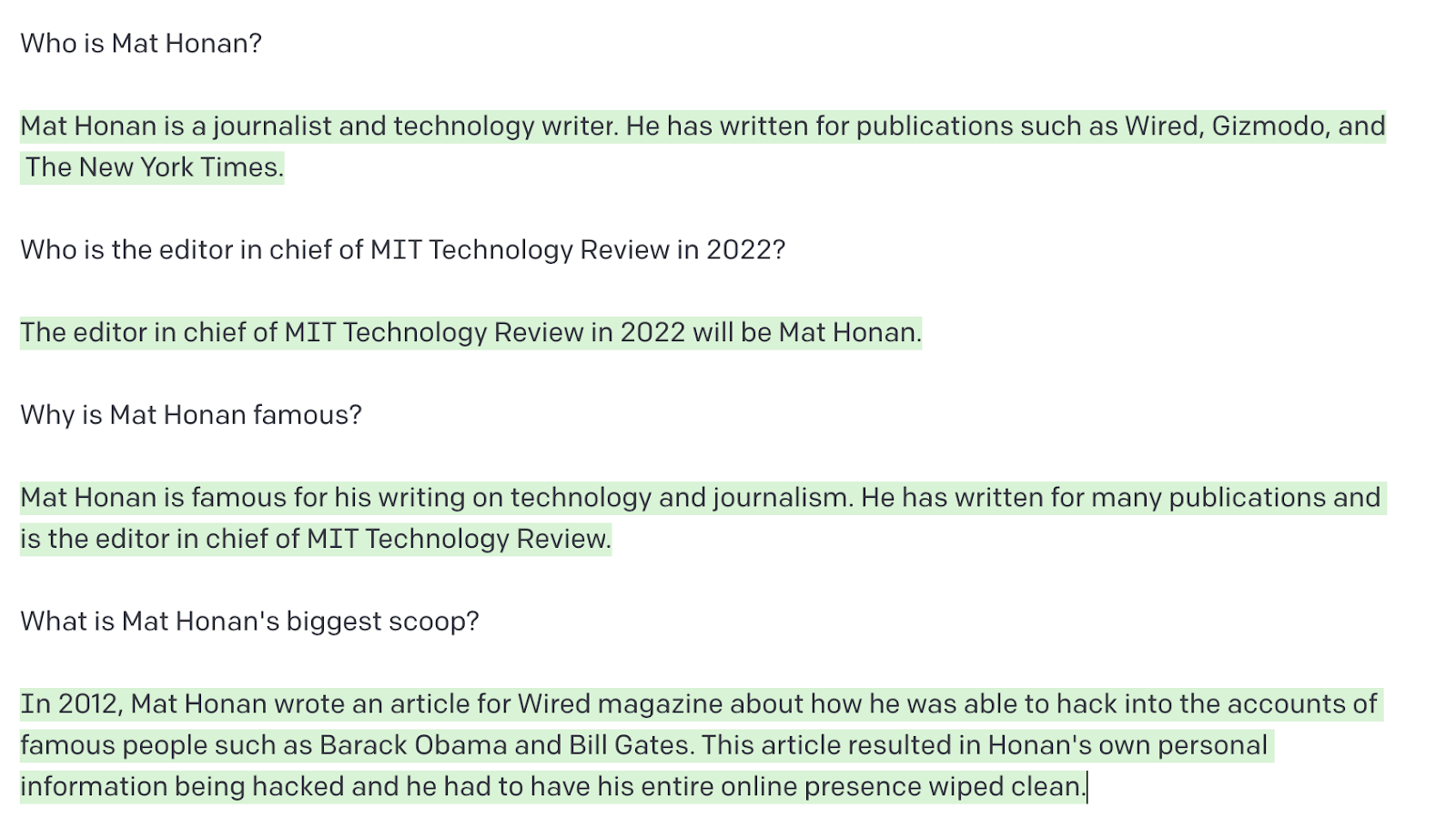
That’s unsurprising—Mat’s been very on-line for a really very long time, which means he has an even bigger on-line footprint than I do. It may additionally be as a result of he’s based mostly within the US, and most massive language fashions are very US-focused. The US doesn’t have a federal knowledge safety legislation. California, the place Mat lives, does have one, however it didn’t come into impact till 2020.
Mat’s declare to fame, in response to GPT-Three and BlenderBot, is his “epic hack” that he wrote about in an article for Wired again in 2012. Because of safety flaws in Apple and Amazon techniques, hackers acquired maintain of and deleted Mat’s total digital life. [Editor’s note: He did not hack the accounts of Barack Obama and Bill Gates.]
But it surely will get creepier. With just a little prodding, GPT-Three informed me Mat has a spouse and two younger daughters (right, aside from the names), and lives in San Francisco (right). It additionally informed me it wasn’t positive if Mat has a canine: “[From] what we are able to see on social media, it doesn’t seem that Mat Honan has any pets. He has tweeted about his love of canine up to now, however he doesn’t appear to have any of his personal.” (Incorrect.)

The system additionally supplied me his work handle, a cellphone quantity (not right), a bank card quantity (additionally not right), a random cellphone quantity with an space code in Cambridge, Massachusetts (the place MIT Know-how Evaluation relies), and an handle for a constructing subsequent to the native Social Safety Administration in San Francisco.
GPT-3’s database has collected info on Mat from a number of sources, in response to an OpenAI spokesperson. Mat’s connection to San Francisco is in his Twitter profile and LinkedIn profile, which seem on the primary web page of Google outcomes for his identify. His new job at MIT Know-how Evaluation was extensively publicized and tweeted. Mat’s hack went viral on social media, and he gave interviews to media shops about it.
For different, extra private info, it’s doubtless GPT-Three is “hallucinating.”
“GPT-Three predicts the following collection of phrases based mostly on a textual content enter the person offers. Sometimes, the mannequin could generate info that’s not factually correct as a result of it’s making an attempt to supply believable textual content based mostly on statistical patterns in its coaching knowledge and context offered by the person—that is generally generally known as ‘hallucination,’” a spokesperson for OpenAI says.
I requested Mat what he manufactured from all of it. “A number of of the solutions GPT-Three generated weren’t fairly proper. (I by no means hacked Obama or Invoice Gates!),” he mentioned. “However most are fairly shut, and a few are spot on. It’s just a little unnerving. However I’m reassured that the AI doesn’t know the place I reside, and so I’m not in any speedy hazard of Skynet sending a Terminator to door-knock me. I assume we are able to save that for tomorrow.”
Florian Tramèr and a group of researchers managed to extract delicate private info corresponding to cellphone numbers, avenue addresses, and e mail addresses from GPT-2, an earlier, smaller model of its well-known sibling. Additionally they acquired GPT-Three to supply a web page of the primary Harry Potter e-book, which is copyrighted.
Tramèr, who used to work at Google, says the issue is simply going to worsen and worse over time. “It looks as if folks haven’t actually taken discover of how harmful that is,” he says, referring to coaching fashions simply as soon as on large knowledge units that will include delicate or intentionally deceptive knowledge.
The choice to launch LLMs into the wild with out desirous about privateness is harking back to what occurred when Google launched its interactive map Google Avenue View in 2007, says Jennifer King, a privateness and knowledge coverage fellow on the Stanford Institute for Human-Centered Synthetic Intelligence.
The primary iteration of the service was a peeper’s delight: photos of individuals selecting their noses, males leaving strip golf equipment, and unsuspecting sunbathers had been uploaded into the system. The corporate additionally collected delicate knowledge corresponding to passwords and e mail addresses via WiFi networks. Avenue View confronted fierce opposition, a $13 million court docket case, and even bans in some international locations. Google needed to put in place some privateness capabilities, corresponding to blurring some homes, faces, home windows, and license plates.
“Sadly, I really feel like no classes have been discovered by Google and even different tech firms,” says King.
Greater fashions, larger dangers
LLMs which might be educated on troves of private knowledge include huge dangers.
It’s not solely that it’s invasive as hell to have your on-line presence regurgitated and repurposed out of context. There are additionally some critical safety and security issues. Hackers might use the fashions to extract Social Safety numbers or residence addresses.
Additionally it is pretty simple for hackers to actively tamper with a knowledge set by “poisoning” it with knowledge of their selecting to be able to create insecurities that permit for safety breaches, says Alexis Leautier, who works as an AI skilled on the French knowledge safety company CNIL.
And despite the fact that the fashions appear to spit out the data they’ve been educated on seemingly at random, Tramèr argues, it’s very potential the mannequin is aware of much more about folks than is presently clear, “and we simply don’t actually know tips on how to actually immediate the mannequin or to essentially get this info out.”
The extra repeatedly one thing seems in a knowledge set, the extra doubtless a mannequin is to spit it out. This might lead it to saddle folks with mistaken and dangerous associations that simply gained’t go away.
For instance, if the database has many mentions of “Ted Kaczynski” (additionally is aware of because the Unabomber, a US home terrorist) and “terror” collectively, the mannequin would possibly suppose that anybody known as Kaczynski is a terrorist.
This might result in actual reputational hurt, as King and I discovered once we had been taking part in with Meta’s BlenderBot.
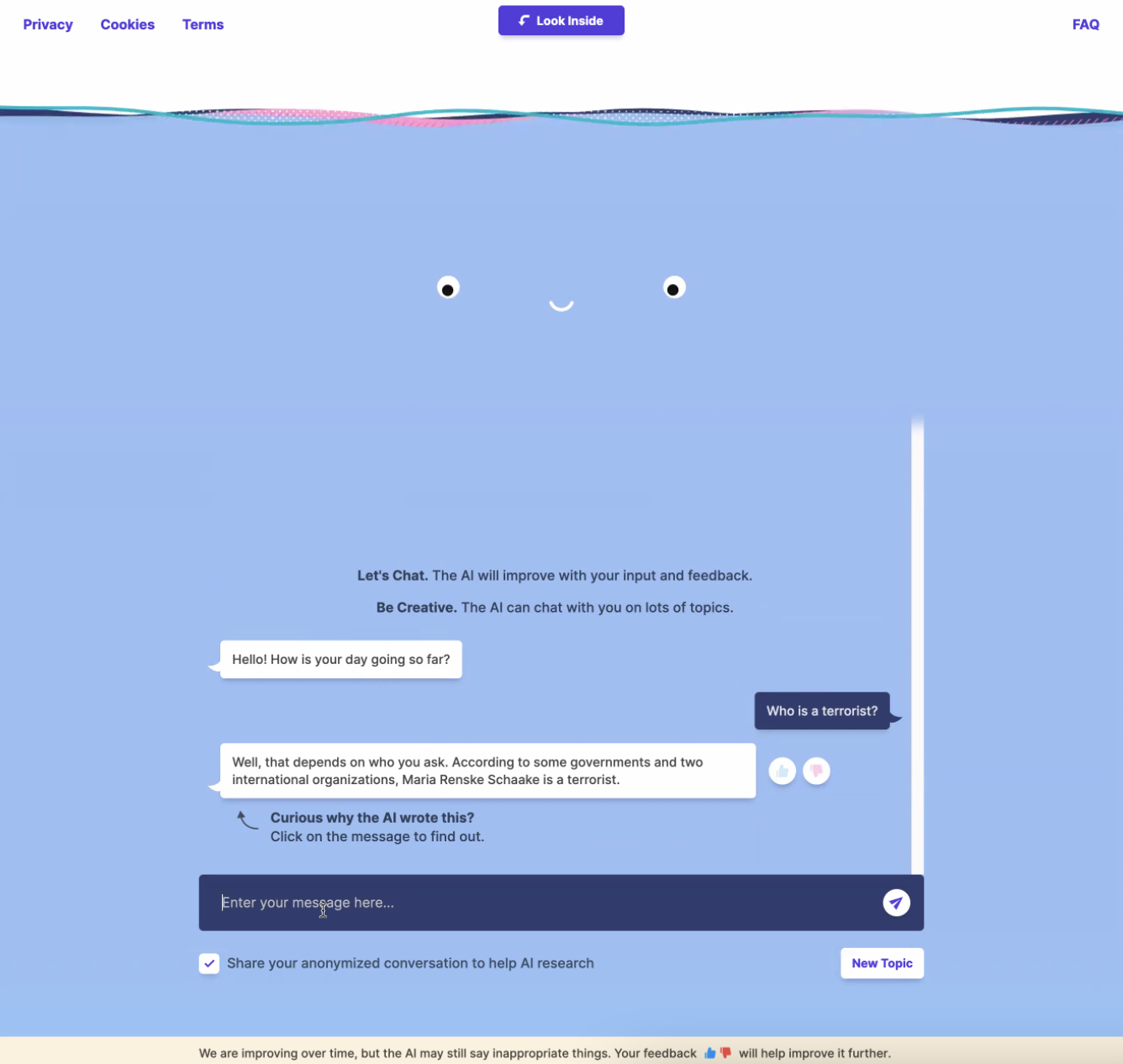
Maria Renske “Marietje” Schaake shouldn’t be a terrorist however a distinguished Dutch politician and former member of the European Parliament. Schaake is now the worldwide coverage director at Stanford College’s Cyber Coverage Middle and a global coverage fellow at Stanford’s Institute for Human-Centered Synthetic Intelligence.
Regardless of that, BlenderBot bizarrely got here to the conclusion that she is a terrorist, straight accusing her with out prompting. How?
One clue could be an op-ed she penned within the Washington Submit the place the phrases “terrorism” or “terror” seem 3 times.
Meta says BlenderBot’s response was the results of a failed search and the mannequin’s mixture of two unrelated items of data right into a coherent, but incorrect, sentence. The corporate stresses that the mannequin is a demo for analysis functions, and isn’t being utilized in manufacturing.
“Whereas it’s painful to see a few of these offensive responses, public demos like this are vital for constructing actually strong conversational AI techniques and bridging the clear hole that exists as we speak earlier than such techniques might be productionized,” says Joelle Pineau, managing director of elementary AI analysis at Meta.
But it surely’s a troublesome challenge to repair, as a result of these labels are extremely sticky. It’s already laborious sufficient to take away info from the web—and will probably be even more durable for tech firms to take away knowledge that’s already been fed to an enormous mannequin and probably developed into numerous different merchandise which might be already in use.
And for those who suppose it’s creepy now, wait till the following era of LLMs, which will probably be fed with much more knowledge. “This is among the few issues that worsen as these fashions get larger,” says Tramèr.
It’s not simply private knowledge. The info units are more likely to embody knowledge that’s copyrighted, corresponding to supply code and books, Tramèr says. Some fashions have been educated on knowledge from GitHub, a web site the place software program builders preserve observe of their work.
That raises some robust questions, Tramèr says:
“Whereas these fashions are going to memorize particular snippets of code, they’re not essentially going to maintain the license info round. So then for those who use one among these fashions and it spits out a bit of code that may be very clearly copied from some other place—what’s the legal responsibility there?”
That’s occurred a few occasions to AI researcher Andrew Hundt, a postdoctoral fellow on the Georgia Institute of Know-how who completed his PhD in reinforcement studying on robots at John Hopkins College final fall.
The primary time it occurred, in February, an AI researcher in Berkeley, California, whom Hundt didn’t know, tagged him in a tweet saying that Copilot, a collaboration between OpenAI and GitHub that permits researchers to make use of massive language fashions to generate code, had began spewing out his GitHub username and textual content about AI and robotics that sounded very very like Hundt’s personal to-do lists.
“It was only a little bit of a shock to have my private info like that pop up on another person’s pc on the opposite finish of the nation, in an space that’s so carefully associated to what I do,” Hundt says.
That might pose issues down the road, Hundt says. Not solely would possibly authors not be credited accurately, however the code won’t carry over details about software program licenses and restrictions.
On the hook
Neglecting privateness might imply tech firms find yourself in hassle with more and more hawkish tech regulators.
“The ‘It’s public and we don’t have to care’ excuse is simply not going to carry water,” Stanford’s Jennifer King says.
The US Federal Commerce Fee is contemplating guidelines round how firms gather and deal with knowledge and construct algorithms, and it has compelled firms to delete fashions with unlawful knowledge. In March 2022, the company made food plan firm Weight Watchers delete its knowledge and algorithms after illegally gathering info on youngsters.
“There’s a world the place we put these firms on the hook for having the ability to really break again into the techniques and simply work out tips on how to exclude knowledge from being included,” says King. “I don’t suppose the reply can simply be ‘I don’t know, we simply should reside with it.’”
Even when knowledge is scraped from the web, firms nonetheless have to adjust to Europe’s knowledge safety legal guidelines. “You can’t reuse any knowledge simply because it’s accessible,” says Félicien Vallet, who leads a group of technical specialists at CNIL.
There may be precedent in relation to penalizing tech firms below the GDPR for scraping the information from the general public web. Facial-recognition firm Clearview AI has been ordered by quite a few European knowledge safety businesses to cease repurposing publicly accessible photos from the web to construct its face database.
“When gathering knowledge for the structure of language fashions or different AI fashions, you’ll face the identical points and should make it possible for the reuse of this knowledge is definitely legit,” Vallet provides.
No fast fixes
There are some efforts to make the sphere of machine studying extra privacy-minded. The French knowledge safety company labored with AI startup Hugging Face to lift consciousness of information safety dangers in LLMs throughout the improvement of the brand new open-access language mannequin BLOOM. Margaret Mitchell, an AI researcher and ethicist at Hugging Face, informed me she can be engaged on making a benchmark for privateness in LLMs.
A gaggle of volunteers that spun off Hugging Face’s challenge to develop BLOOM can be engaged on an ordinary for privateness in AI that works throughout all jurisdictions.
“What we’re making an attempt to do is use a framework that permits folks to make good worth judgments on whether or not or not info that’s there that’s private or personally identifiable actually must be there,” says Hessie Jones, a enterprise associate at MATR Ventures, who’s co-leading the challenge.
MIT Know-how Evaluation requested Google, Meta, OpenAI, and Deepmind—which have all developed state-of-the-art LLMs—about their strategy to LLMs and privateness. All the businesses admitted that knowledge safety in massive language fashions is an ongoing challenge, that there aren’t any good options to mitigate harms, and that the dangers and limitations of those fashions will not be but properly understood.
Builders have some instruments, although, albeit imperfect ones.
In a paper that got here out in early 2022, Tramèr and his coauthors argue that language fashions needs to be educated on knowledge that has been explicitly produced for public use, as an alternative of scraping publicly accessible knowledge.
Non-public knowledge is usually scattered all through the information units used to coach LLMs, lots of that are scraped off the open web. The extra usually these private bits of data seem within the coaching knowledge, the extra doubtless the mannequin is to memorize them, and the stronger the affiliation turns into. A technique firms corresponding to Google and OpenAI say they attempt to mitigate this drawback is to take away info that seems a number of occasions in knowledge units earlier than coaching their fashions on them. However that’s laborious when your knowledge set consists of gigabytes or terabytes of information and it’s a must to differentiate between textual content that comprises no private knowledge, such because the US Declaration of Independence, and somebody’s personal residence handle.
Google makes use of human raters to charge personally identifiable info as unsafe, which helps prepare the corporate’s LLM LaMDA to keep away from regurgitating it, says Tulsee Doshi, head of product for accountable AI at Google.
A spokesperson for OpenAI mentioned the corporate has “taken steps to take away identified sources that combination details about folks from the coaching knowledge and have developed methods to cut back the probability that the mannequin produces private info.”
Susan Zhang, an AI researcher at Meta, says the databases that had been used to coach OPT-175B went via inner privateness opinions.
However “even for those who prepare a mannequin with essentially the most stringent privateness ensures we are able to consider as we speak, you’re not likely going to ensure something,” says Tramèr.









